Drug Checking Chemical Dictionary
Building a unicorn tool to publicly organize street drug information.
Because no single expert speaks all four languages of the drug supply
Drug checking has a communication problem. When a substance is identified in drug checking, the substance means something very different to a forensic chemist, an clinician/pharmacologist, a harm reduction outreach worker, and an epidemiologist. Each of them holds a piece of the picture. None of them holds the whole thing.
The Drug Checking Chemical Dictionary is an attempt to create shared metadata database that speaks all four professional languages simultaneously, linking laboratory detection to clinical care, harm reduction practice, and population-level health trends. And it'll all be public.

Four domains of drug knowledge
Understanding what is in the street drug supply requires expertise that does not exist in any single profession.
- IDENTIFICATION: A forensic chemist can tell you exactly what molecule is present and in what quantity.
- BIOMEDICAL: A pharmacologist can characterize a new substance in the lab. A toxicologist or pharmacist can tell you what that molecule does to the human body. An addiction medicine specialist can tell you about dependence potential.
- STREET SMARTS: A harm reduction worker knows behaviors, what it is called on the street, how it's used, and what people actually need to know.
- TRENDS: An epidemiologist knows whether it is new, spreading, and how it fits into trends over time and geography. OG drug scientists can provide historical context. International partners can help us see across borders.
These four domains of knowledge are rarely held by the same person, and no profession has full expertise across all four domains.
| Domain | Core expertise |
|---|---|
| Identification | Analytical chemistry, forensic science, machine-based drug checking |
| Biomedical | Toxicology, addiction medicine, pharmacology |
| Street smarts | Harm reduction outreach, lived experience, peer knowledge |
| Trends | Epidemiology, regulatory context, history, geographic patterns |
The Chemical Dictionary is designed to sit at the center of all four domains, to be a shared reference that makes each professional more effective without requiring anyone to become an expert in everything.
Synchronizing Drug Names
The names of substances found in street drugs were not designed for public health communication. They were assigned by chemists for chemists, according to nomenclature conventions that vary by discipline, country, and decade.
The UNC Street Drug Analysis Lab has confirmed over 500 unique substances in community-donated samples since 2021. Partners at the University of Victoria have identified over 700. Without a shared naming and classification layer, data from these programs cannot be meaningfully combined to understand broader patterns. Emerging substances detected in one city cannot be efficiently flagged across a national network. And when a sample donor or drug checking technician sees a result containing a name they have never seen, they paste it into a search engine and get a scientific journal abstract or a DEA scheduling notice, neither of which tells them what they actually need to know. Garbage, and a frustrating waste of time.
The same substance can appear as medetomidine in an analytical chemistry report, dexmedetomidine in a clinical record, and be called tranq on the street. General use, AI, and specialized search engines do not treat these as synonyms, resulting in missed information. Programs trying to aggregate findings across sites can find their naming systems to not align perfectly, leading to tedious recoding by hand.
Why we're building this
The absence of a chemical classification layer creates concrete knowledge gaps. Here are are few examples we have faced, and could name dozens more!
- If two samples contain
fentanylandmetonitazene, there is currently no reliable programmatic way to identify that both are synthetic opioids. A human expert knows this. The data system does not. - Naming of orphines is a mess: N-propionitrile chlorphine = chlorphine = cychlorphine. So which one do we use?
- There is no reliable way to systematically identify substances that naturally occur together to differentiate from adulterants, like heroin impurities
6-MAM,acetylcodeine, etc. But it would be helpful for sample donors to know what naturally occurs in heroin to focus unwanted cuts. Luckily, a recently completed project (funded by FDA, led by the University of Kentucky) hand-coded thousands of name variants and substances to create roll-up categories to simplify substance identification. We will rely on this incredible resource to help classify substances. - A relatively new ketamine-like dissociative can be called:
2F-NENDCK(in Australia),CanKeton the street,2-fluoro-N-ethylnordeschloroketamineby chemists,2-FXEonline, and2-fluoro-2-oxo-PCEby drug checking programs. Comparing across countries is really difficult, and search engines aren't great at figuring out these related names. And what do you tell someone who's sample contains it?
What it will contain
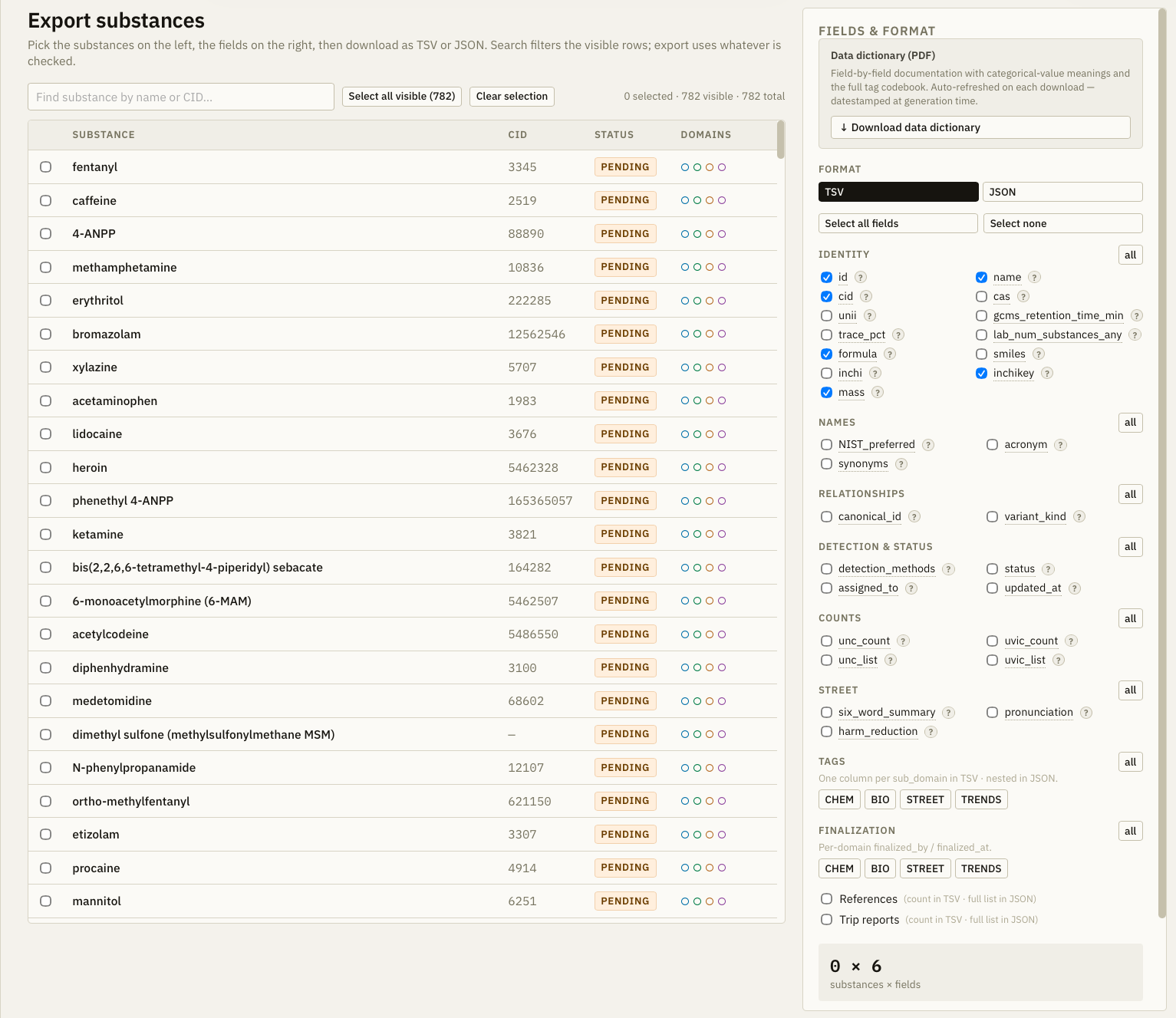
Each entry in the chemical dictionary is anchored to a PubChem CID — the National Library of Medicine's unambiguous chemical identifier — and then extended across 12 structured fields designed to serve every audience simultaneously. Here is a simplified example:
| # | Field | Description | Example |
|---|---|---|---|
| 1 | Preferred name | Standardized name provided by NIST | p-fluorofentanyl |
| 2 | Identification | Tags for molecular properties and classifications | opioid; synthetic; opioid analogue |
| 3 | Biomedical | Tags for pharmacological properties, toxicology biological effects, addiction med/science, health risks | overdose risk; CNS depressent; dependence; tolerance |
| 4 | Street Smarts | Tags for context of current real-world use | downer; smoked; snorted; injected; street |
| 5 | Trending | Tags for trends in prevalence, rare vs. common, geographic distribution | common; declining [USA]; steady [Canada] |
| 6 | PubChem CID linkage | Canonical NIH/NLM identifier for cross-database linkage | 62300 |
| 7 | SMILES formula | Molecular structure in open-source notation for cheminformatics linkage | CCC(=O)N(C1CCN(CC1)CCC2=CC=CC=C2)C3=CC=C(C=C3)F |
| 8 | Synonyms | Name variants across chemical conventions, abbreviations, countries | para-fluorofentanyl; 4-fluorofentanyl; |
| 9 | Pronunciation guide | Plain-language syllable guide for clinical and outreach settings | pee-FLOOR-oh-FEN-tuh-nil |
| 10 | Six-word summary | Plain-language description for sample result delivery, app integration, and field communication | Fentanyl-like opioid, overdose risk |
| 11 | Vernacular and street names | Slang and brand names to aid website search and harm reduction communication | down |
| 12 | References | Curated links to scientific literature for in-depth learning | PubMed, scientific articles, news articles, videos, trip reports |
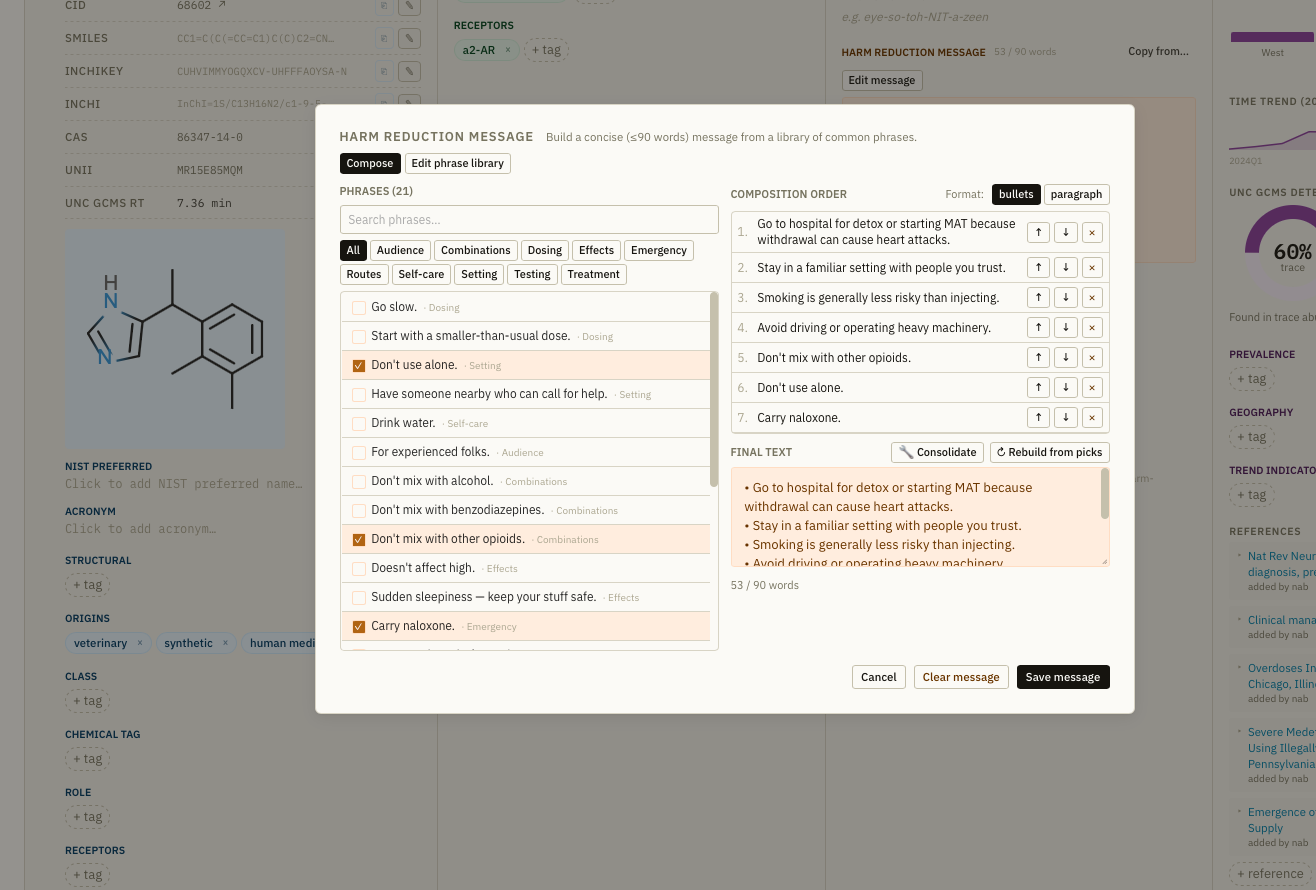
A later phase may also include another field for harm reduction advice, but we believe so much of that is dependent on local and individual context.
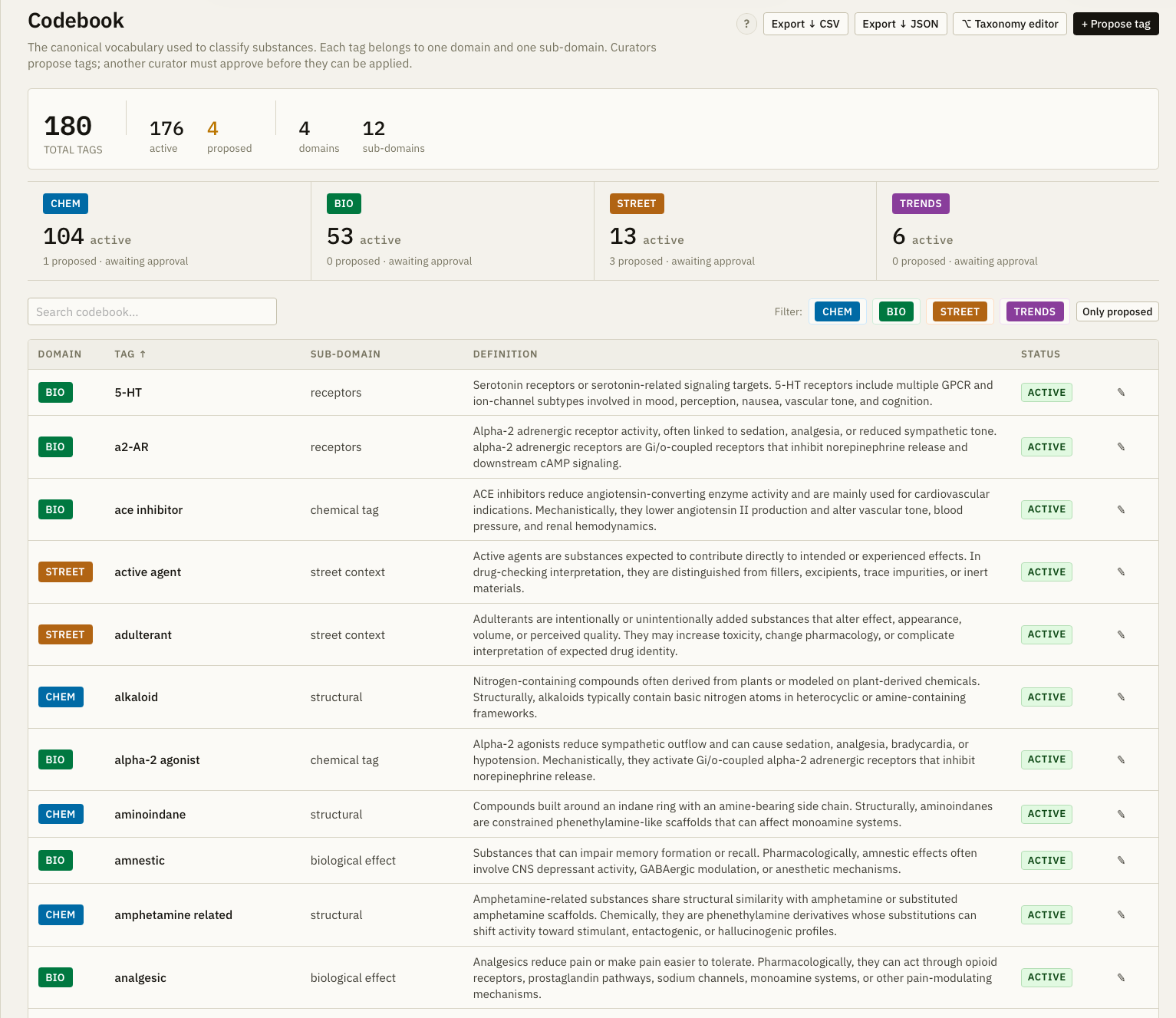
Why Tags?
Most classification systems are hierarchical and put things in boxes. But you may need more flexibility depending on your information needs. For example, you may want to classify all your samples by if they are plant-grown or synthetic. Or, you may want to differentiate GABAergic versus noradrenergic activity. Or, you may want to pick out uppers vs. downers vs. hallucinogens to figure out what a mix of substances in a sample may feel like. Our flexible tagging structure let's you building your own classification system (ontology). It also helps the different expertise on our team stay in their lanes. This is some super nerdy data engineering, but it could lead to data analyses that are much more real-world salient.
How we are building it
The development process runs in 6 phases, drawing on diverse expertise and review before public release. University of Victoria and the American College of Medical Toxicology will be collaborating with UNC to make this happen. We expect completion sometime in 3Q2026.
Phase 1 — Data collection
Collect examples of similar classification efforts by others, and decide which makers to collaborate with as starting point. Got others? Share them with us at opioiddatalab@unc.edu.
Phase 2 — Name standardization
Compile naming conventions from across drug checking and forensic sciences, surface conflicts, and establish standardized naming convention. [Now being conducted by NIST 🙏🏽]
Phase 3 — Classification
Tag each substance across the four knowledge domains using input from chemists, toxicologists, harm reduction specialists, and epidemiologists. Substances will carry tags from more than all four domains.
Phase 4 — Discrepancy review
Adjudicate primary identifiers for each substance and determine preferred name variants through expert review, scientific literature, and professional consensus.
Phase 5 — Community feedback & revision
Once a working prototype has been developed, we will invite the Alliance for Collaborative Drug Checking (ACDC) network and selected international partners to kick the tires and make suggestions. Feedback will be incorporated into a revision.
Phase 6 - Public release
Release via public website, RESTful API, and downloadable CSV, and full documentation. Devise plan to keep updated.
Who this serves
ChemDict is designed for many audiences, each of whom has different needs from the same underlying metadata.
Harm reduction programs
Frontline staff who communicate drug checking results directly to sample donors. The six-word summaries are designed for rapid, plain-language delivery in the field, where a long chemical name and a Google search result are not useful to anyone. The vernacular field connects laboratory terminology to the language that donors actually use.
Data analysts
Epidemiologists and data scientists who analyze tabular drug checking data and need to group substances by pharmacological class. The classification layer makes it possible to ask population-level questions — how many opioid samples, how many stimulant samples, how many samples containing novel psychoactive substances — that are currently unanswerable at scale. Applicable to drug checking data, clinical data, and autopsy lab outputs.
Drug checking programs
Chemistry labs newly entering the field who need a classification framework from day one. The synonym list and preferred name conventions allow a new program to align its data output with established nomenclature without building its own classification system from scratch.
Clinicians
When a new substance is detected in the clinic or hospital, having a quick resource to help contextualize it can speed up the process of figuring out how to treat the patient. Fewer delays, fewer name mixups, better care.
Software developers
Teams building dashboards, reporting tools, apps, or alert systems from drug checking data who need a ready-made categorization layer. The RESTful API enables real-time lookup so that applications can classify substances programmatically without manual intervention.
Preview
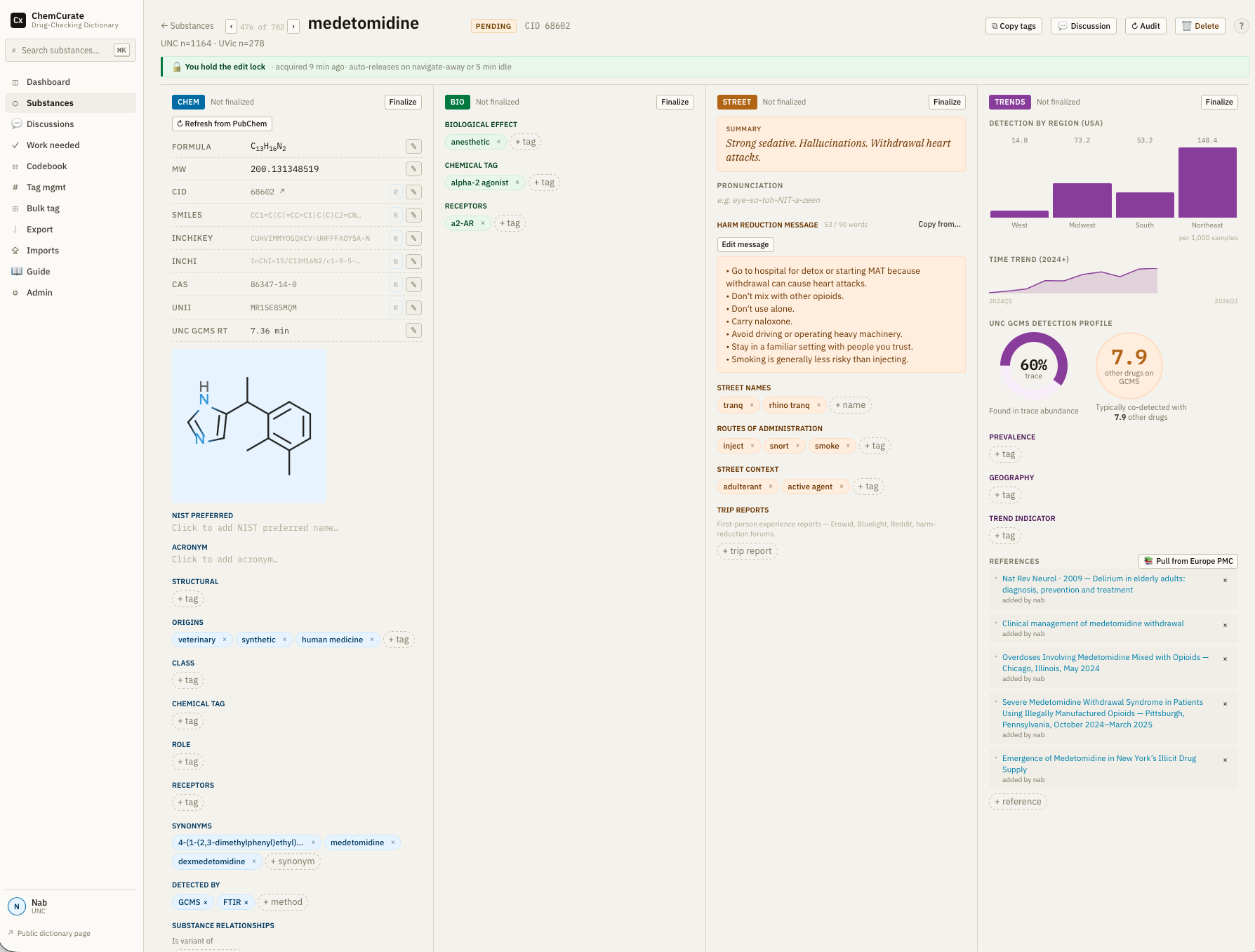
A working prototype of the Chemical Dictionary Explorer is publicly available. It currently covers 200+ substances with approximately 70 classification tags. It's not complete, but more a demo of where we are headed.
Prototype
We are building an advanced curation platform to consolidate the information.
Who's Involved
Makers
- Street Drug Analysis Lab at the University of North Carolina at Chapel Hill
- University of Victoria, BC, Canada
- American College of Medical Toxicology
- Center for Prevention Services & Queen City Harm Reduction (Charlotte, NC)
Collaborators
- National Institute for Standards and Technology (NIST) RaDAR
- Center for Forensic Science Research and Education (CFSRE)
- Alliance for Collaborative Drug Checking (ACDC)
Funder
- Foundation for Opioid Response Efforts (FORE)
Public Input
We will be soliciting input from drug checking service providers and people with lived experience during the development process.